
Danışmanlık hizmetlerimiz içerisinde bulunan bakım anlaşmasında sizlere verdiğimiz birçok desteğin yanında, bakım anlaşmasına dahil olan sunucuları 7/24 izlemek de dahildir. Bakım anlaşması kapsamına dahil olan sunucularınızı seneler içerisinde geliştirdiğimiz ve sürekli olarak güncellediğimiz Kangal ile birçok açıdan izliyor ve gerekli müdahaleleri yapıyoruz.
Eğer;
- Beklenmeyen veya dikkatsizlik nedeniyle oluşabilecek sorunlar için, sorun henüz bir kesintiye neden olmadan ve son kullanıcıya yansımadan haberdar olmak istiyorsanız,
- Gerek finansal, gerekse firmanın imajı açısından kesintiye tahammülünüz yoksa,
- Geçmişe dönük olarak veritabanı sorun tespit çalışması yapabilmek istiyorsanız,
- Ve veritabanı sunucularınızın durumunu yakından takip etmek istiyorsanız, bakım anlaşması kapsamında verdiğimiz hizmet tüm bu ihtiyaçlarınıza fazlasıyla cevap verecektir.
Bu çerçevede otomatik olarak yapılan ve haklarında ilgili kişilere alarm, bilgilendirme, uyarı ve hata e-postaları gönderilen denetim ve diğer işlemlere birkaç örnek:
- Login’ler (kullanıcılar) başka bir sunucuya yedeklenir,
- İşlemlerin bloklanma durumu, başka sebeplerle biriken işlemler, açık kalan işlemler ve uzun süren işlemler kontrol edilir,
- CPU kullanımı kontrol edilir,
- Disk cevap süreleri ve disklerdeki boşluk oranları kontrol edilir,
- Anormal tablo büyümeleri kontrol edilir,
- (Varsa) Always On Availability Group replikasyon gecikme, üye sunucunun kapanması, performans sorunları kontrol edilir,
- Veritabanı ve Transaction Log yedeklerinin alınıp alınmadığı kontrol edilir,
- Veritabanı sunucusuna gerçekleştirilen fazla hatalı girişler ve anormal bağlantılar kontrol edilir,
- Tüm veritabanlarındaki tüm işlemlerin oluşturduğu yükler kayıt altına alınır ve geriye dönük olarak kontrol edilebilir,
- Hata alan SQL Server Agent Job’ları kontrol edilir,
- Error Log dosyası kritik ve beklenmeyen hata ve uyarı mesajları için kontrol edilir,
- Veritabanlarında yapılan tüm tablo, SP, indeks, Trigger gibi nesneleri oluşturma/değiştirme ayrıntıları kayıt altına alınır,
- Kullanışsız indeksler, olası eksik indeksler, son 2 haftalık sistem performansı, hata alan Job’lar için çeşitli raporlar gönderilir.
Aşağıdaki sayfalarda, yukarıda değinilen kontrollerden bazıları için gönderilen alarm, bilgi, uyarı ve hata e-postalarından örnekler sunulmaktadır.
Notlar:
- Olabildiğince çok şirket ve çalışana hitap edebilmek için tüm e-postalar ingilizce dilinde düzenlenmiştir.
- Tüm kontrollerin eşik değerleri bir parametre tablosundan değiştirilebilmektedir.
- Örnekler, gerçek müşterilere gelen gerçek e-postalar olduğundan kritik yerler mozaiklenmiştir.
Örnek:
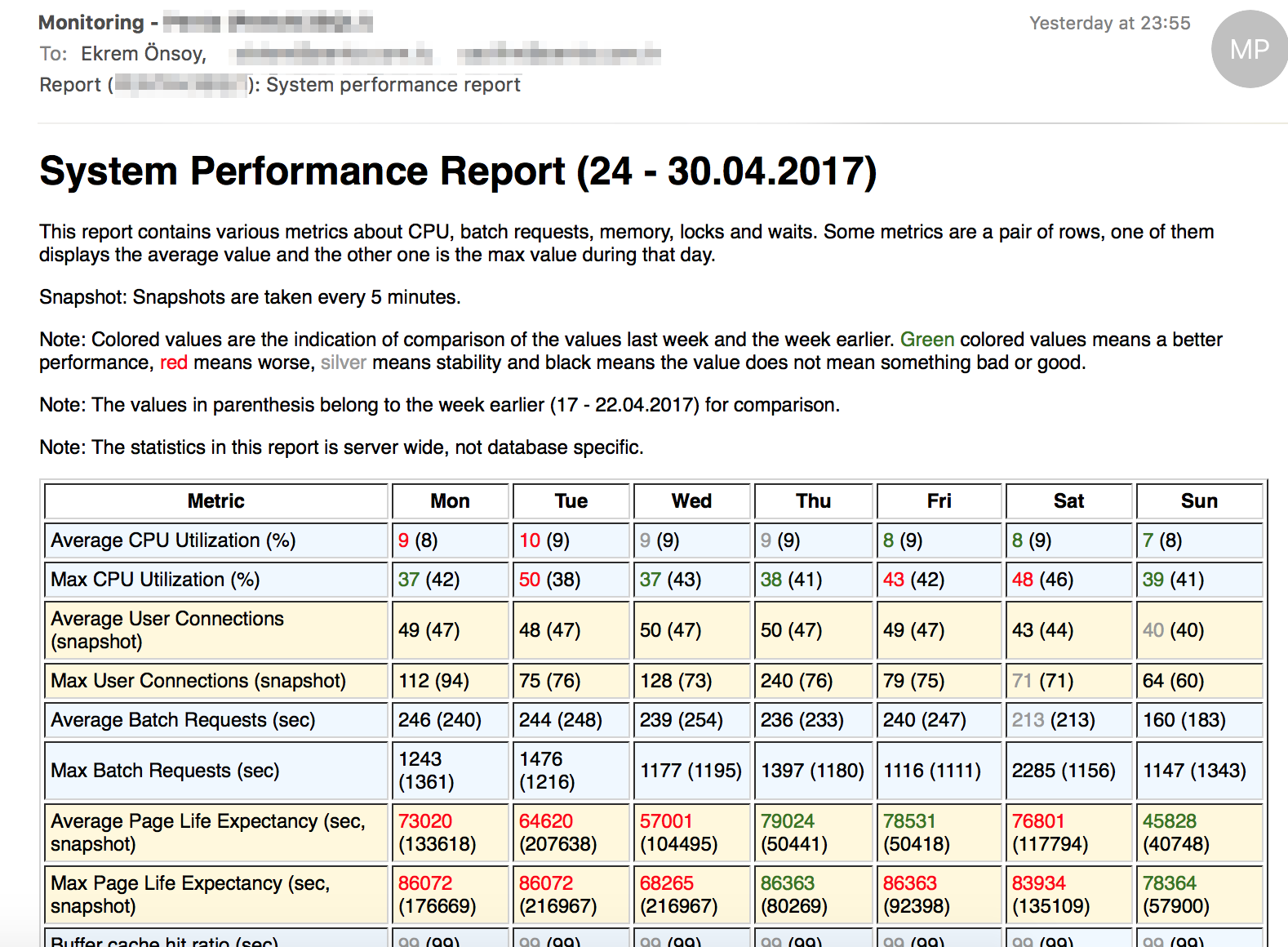
Aşağıdaki rapor haftalık olarak Pazar geceleri gönderilmektedir. Bu raporda, tek bir bakışta karşılaştırma yapılabilmesi için hem son bir haftanın değerleri, hem de parantezler içerisinde ondan önceki haftanın değerleri gösterilmektedir.
Not: Bu ekran görüntüsünde rapor kısmi olarak görüntülenmektedir.
Örnek:
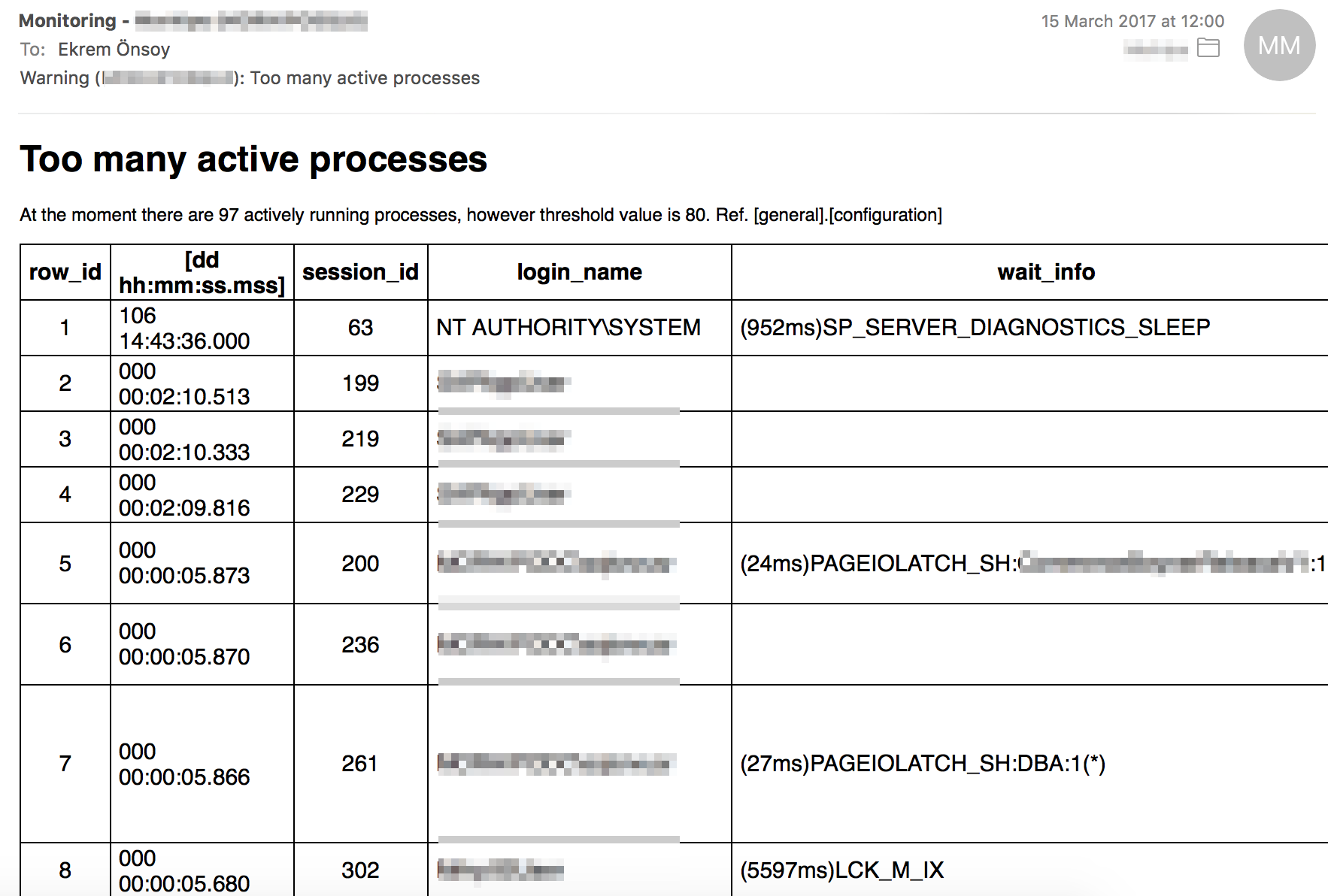
Bazen Blocking nedeniyle, bazen hatalı derlenen bir plan ile çalışan bir sorgunun CPU ve hafıza üstünde yarattığı baskı nedeniyle işlemler bloke olabilmektedir. Aşağıdaki uyarı da bu gibi durumlarda oldukça faydalıdır. Bu rapor sayesinde bilgisayar başında olmaya bile gerek kalmadan bir bakışta sorunun hangi kullanıcı ve işlem nedeniyle olduğu görülebilmektedir.
Örnek:
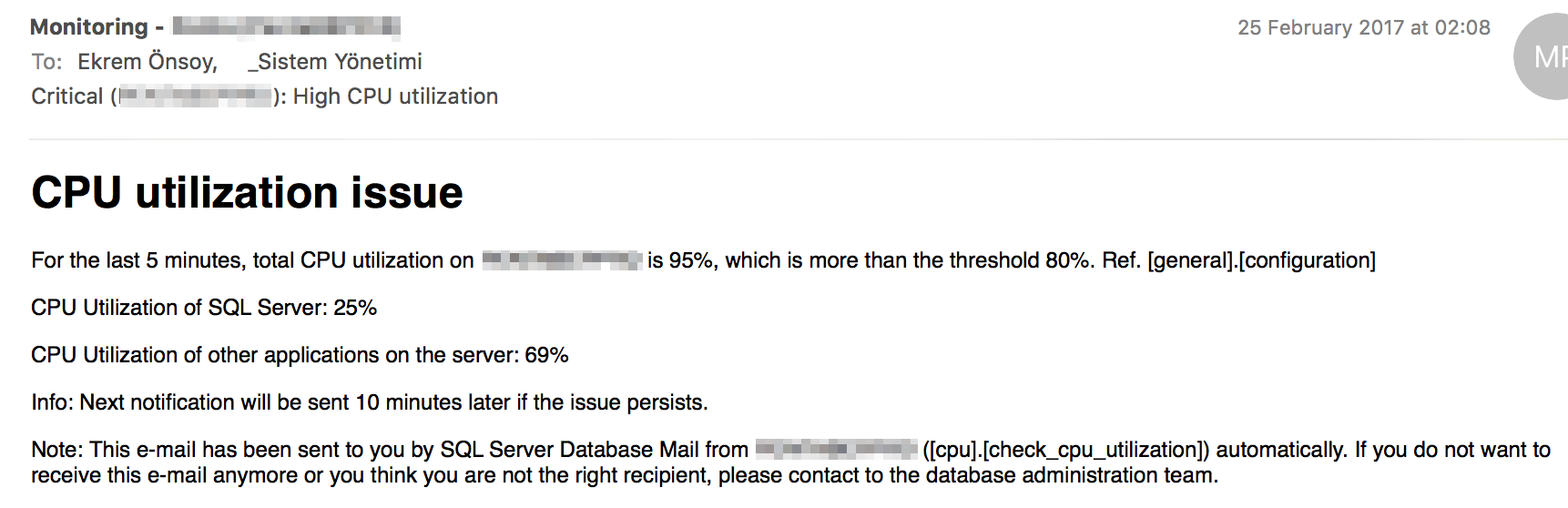
Mesela son beş dakika içerisinde CPU kullanımı X değerinin üzerinde olursa aşağıdaki gibi bir e-posta gelir. Aşağıdaki örnekte olduğu gibi bazen sorun doğrudan veritabanından kaynaklanmaz. Gerek böyle durumları, gerekse veritabanındaki CPU kullanımını bu alarm ile takip ederiz.
Örnek:
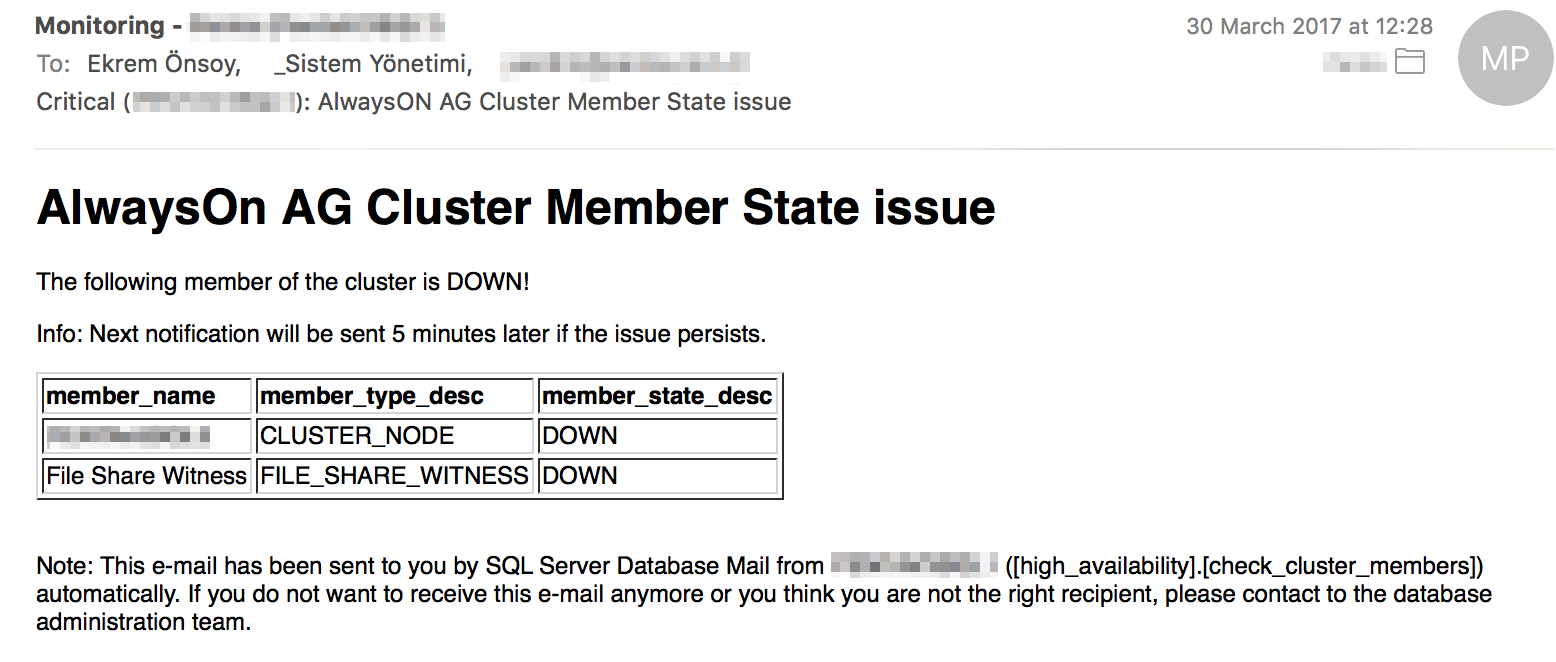
Eğer sisteminizde Transactional Replication, Database Mirroring, Clustering veya Always On Availability Groups gibi özellikler etkin olarak kullanılıyorsa bunları özellikle yakından takip etmek istersiniz. Çünkü canlı birincil sunucunuz sağlam olsa da, örneğin aşağıdaki durumda olduğu gibi 3 üyeden oluşan Cluster’ınızdaki 2 üye herhangi bir nedenle hizmet veremez duruma gelirse Cluster’ınız kapanır ve birincil sunucunuz da hiçbir sorunu olmasa dahi hizmet veremez duruma gelir.
Aşağıdaki gibi bir uyarıyla bu ve benzer durumlardan hemen haberdar oluruz.
Örnek:
Veritabanı sunucunuzda bir hata oluştuğunda ilk bakılacak yerlerden biri Error Log dosyasıdır. Fakat bu dosyaya yazılan hata mesajlarını varsayılan olarak manuel takip etmek gerekiyor. Fakat aşağıdaki rapor ile Error Log’ta oluşan tüm kritik olabilecek hatalardan hemen haberdar olabiliyoruz. Haberdar olmak istemediğimiz hata mesajları için de istisna tanımlamaları yapabiliyoruz.
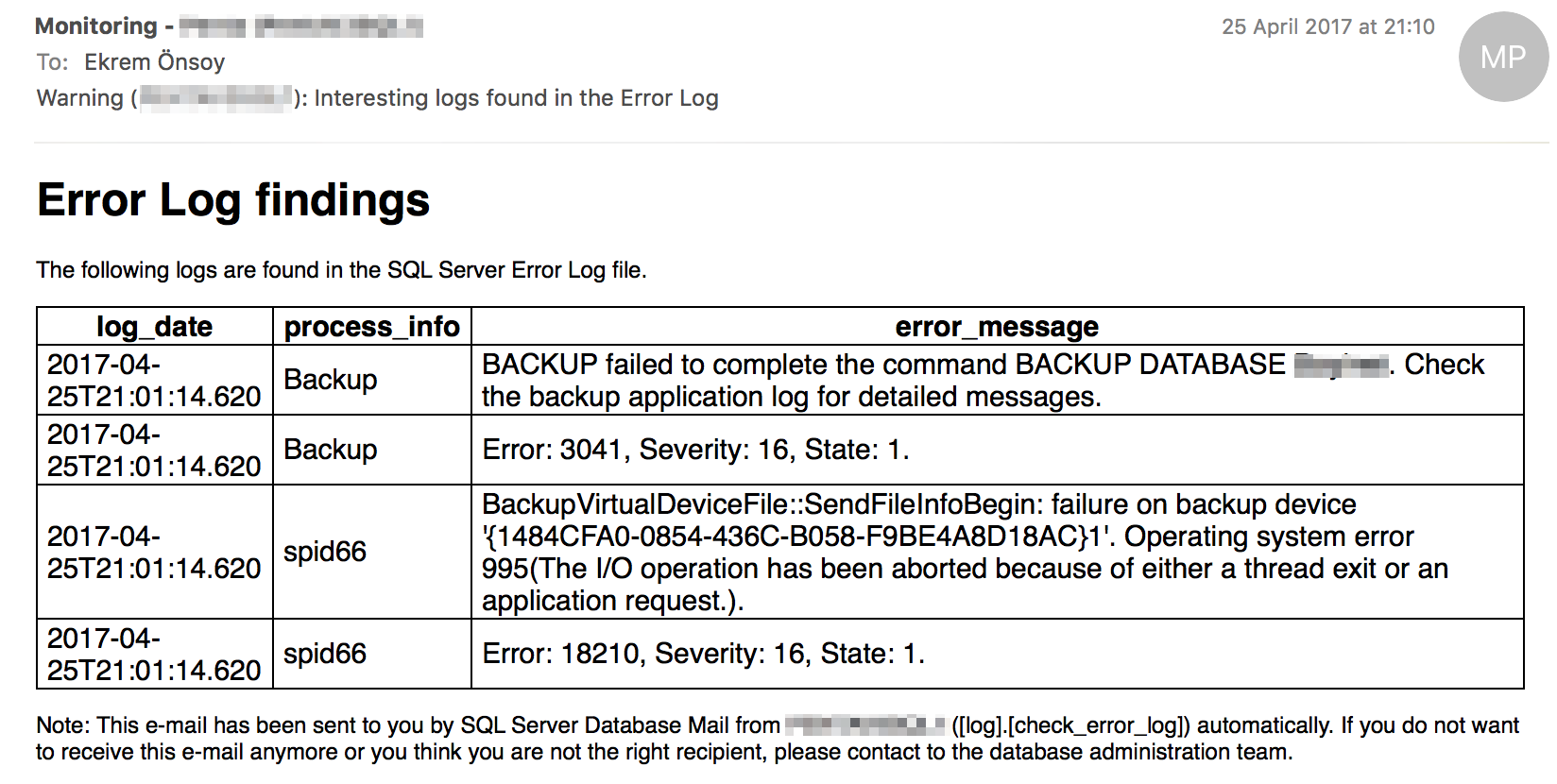
Örnek:
Gerek SQL Server’da, gerekse diğer ürünlerdeki kişisel ihtiyaçlarınız için kişisel çözümler üretmeniz gerekiyor. Aşağıdaki rapor da böyle bir gereksinimden yola çıkılarak üretildi. Herhangi bir veritabanınızdaki herhangi bir tablonuz dün X boyutundayken bugün birden Y boyutuna geldiğinde bunu bilmek isteyebilirsiniz, çünkü bu genelde anormal bir duruma işaret eder.
Aşağıdaki rapor da zaten kendini anlatıyor. Belirlediğimiz eşik değerleri geçerek büyüyen tabloları aşağıdaki örnekte olduğu gibi takip edip, olası anormallikleri olaylar çığrından çıkmadan tespit edebiliyoruz.
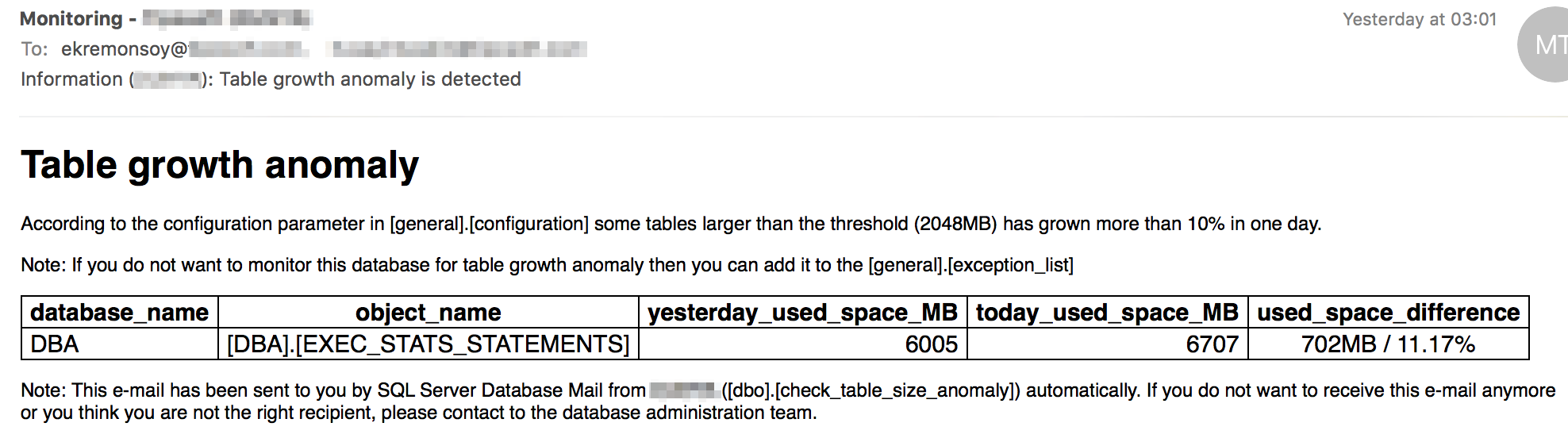
Örnek:
Konu veritabanlarına gelince yedekleme yapılacak işlerin en başında gelir. Sağlıklı ve güvenli bir şekilde yedeklenmeyen ve yedeklerin alınıp alınmadığının sıkı bir şekilde takip edilmediği durumlarda felaket er ya da geç gelir.
Veritabanı yedeklemesi konusunda şöyle kontroller yapıyoruz:
- Yedek alınırken tutarlılık kontrolü,
- Yedek alınırken hata oluşursa diye kontrol,
- Yedeği alınmamış veritabanlarının kontrolü
Ve aşağıdaki rapor ile de tüm veritabanları için pozitif yedek kontrolü yapılmaktadır. Yani veritabanlarının yedeği alınsa da, alınmasa da aşağıdaki rapor günlük olarak üretilir. Böylece bu hayati derecedeki önemli konuda herhangi bir aksaklık yaşanmaması sağlanır.
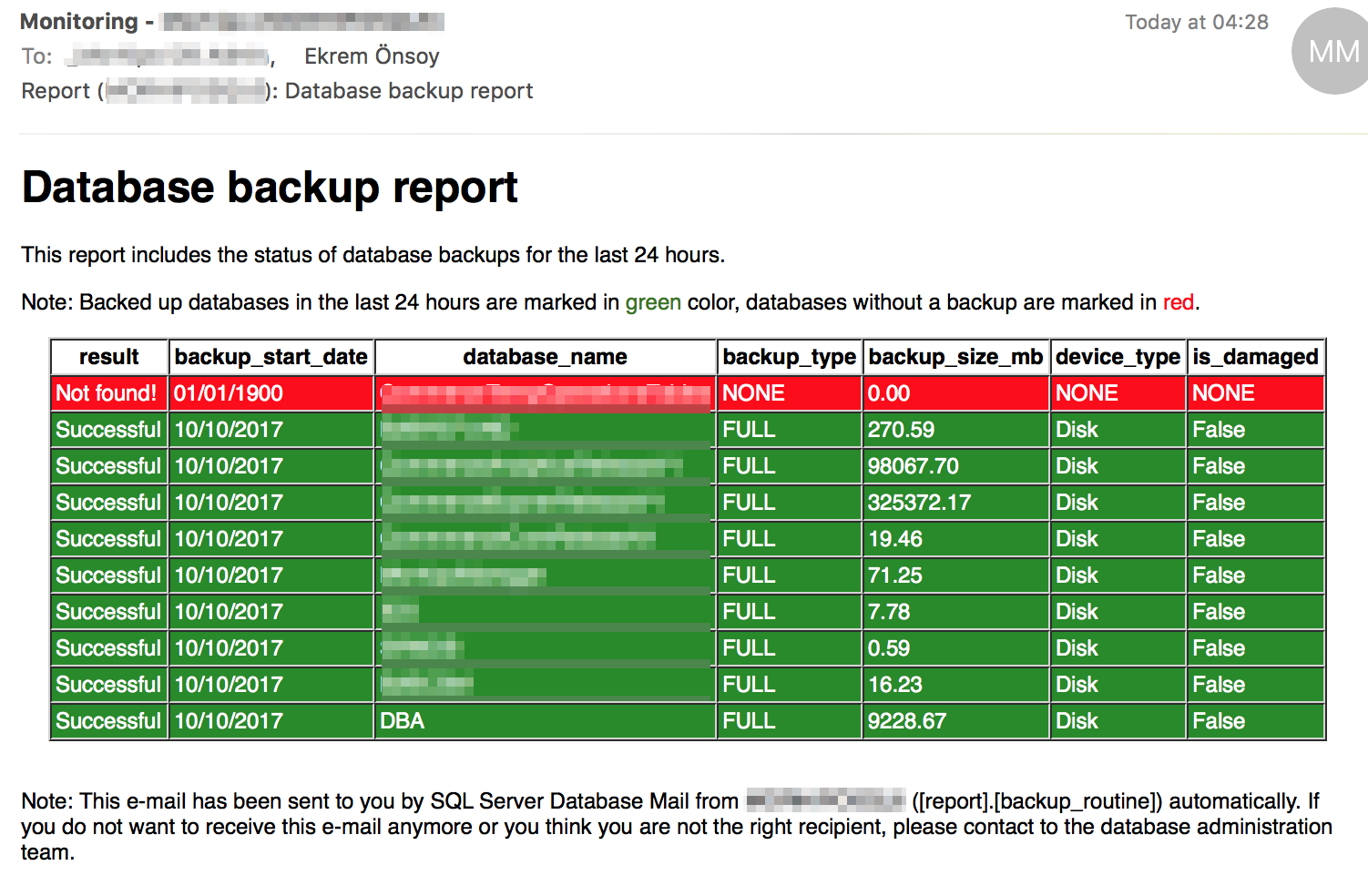
Örnek:
Aşağıda ekran görüntüleri bulunan kontrol bir iç performans takip uygulamasıdır. Yani bu bilgiler e-posta ile gönderilmez, bir sorun anında, rutin kontrollerde veya performans iyileştirme çalışmalarında bu uygulama kullanılarak en masraflı işlemler, ne kadar sıklıkla çalıştıkları, ne kadar kaynak tükettikleri ve ne kadar sürdükleri belirlenebilir. Yani işlemlerin karakutusu gibidir.
Her 5 dakikada yeni bir paket üretilir, aşağıdaki ekranda 5’er dakikalık paketler görünmektedir.
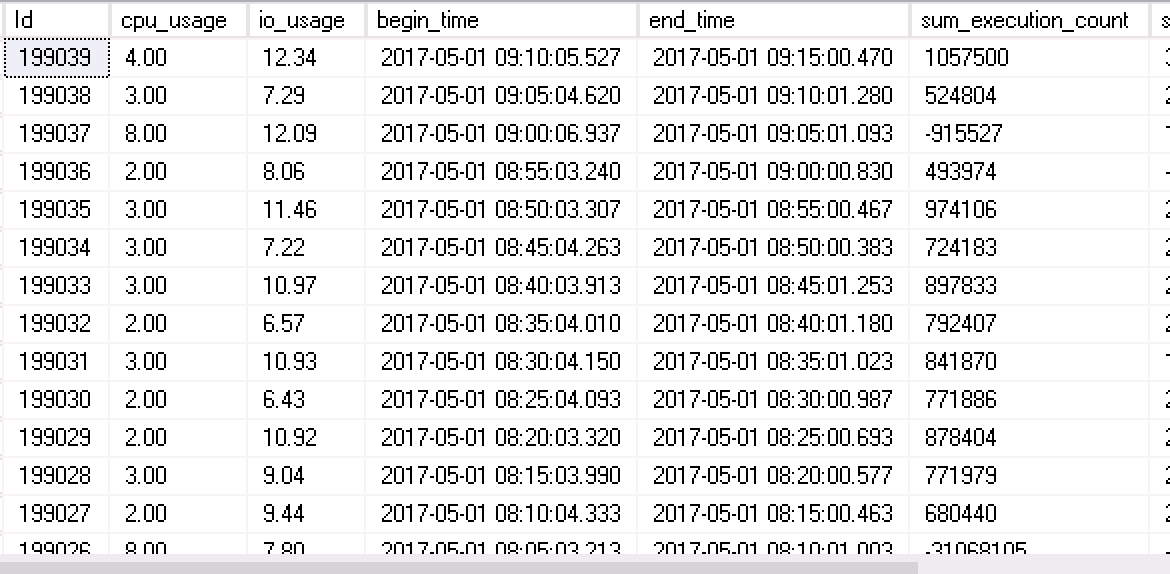
Her bir paketin içeriği de aşağıdaki gibidir. Örneğin aşağıda 1 Mayıs 2017 saat 09:10 ile 09:15 arasındaki işlemler ve bunların yoğunluklarının ayrıntıları görüntülenmektedir. Böylece tek bir bakışta hangi saat aralığında ne kadar yoğunluk olduğu ve yoğunluğu hangi işlemlerin oluşturduğu görülebilmektedir.
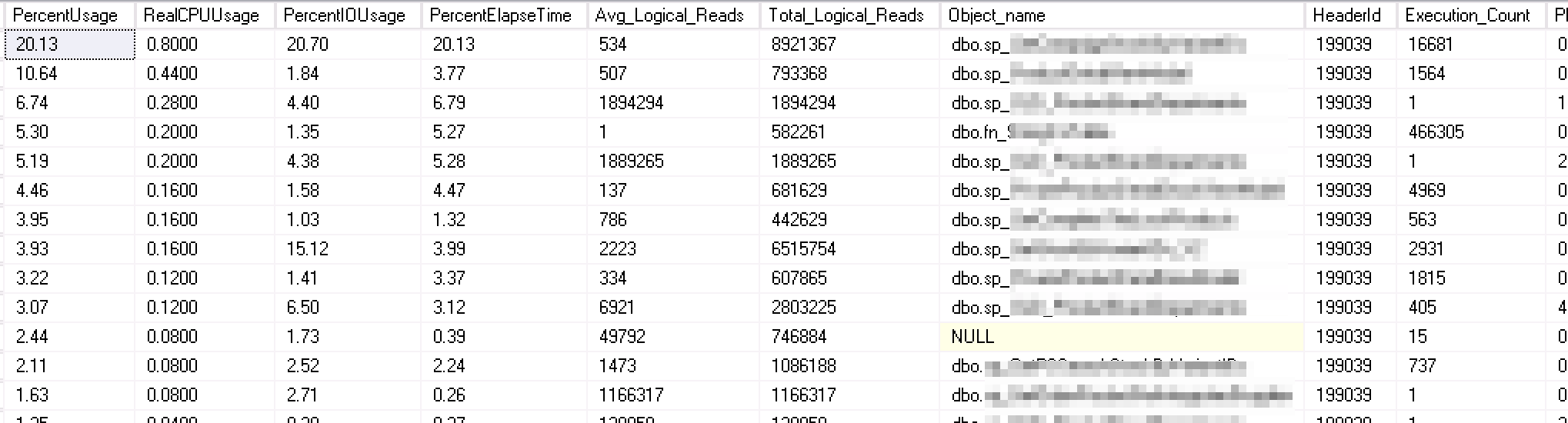
Örnek:
Önceden de belirtildiği gibi kontroller birçok açıdan yapılmaktadır, buna güvenlik de dahildir. Aşağıdaki ilk ekran görüntüsünde sunucuya yapılmış anormal bir bağlantı tespit edilmiştir. Diğer kontrol ile de akın şeklinde yapılan (Brute Force/Dictionary) olası saldırılar izlenmektedir.
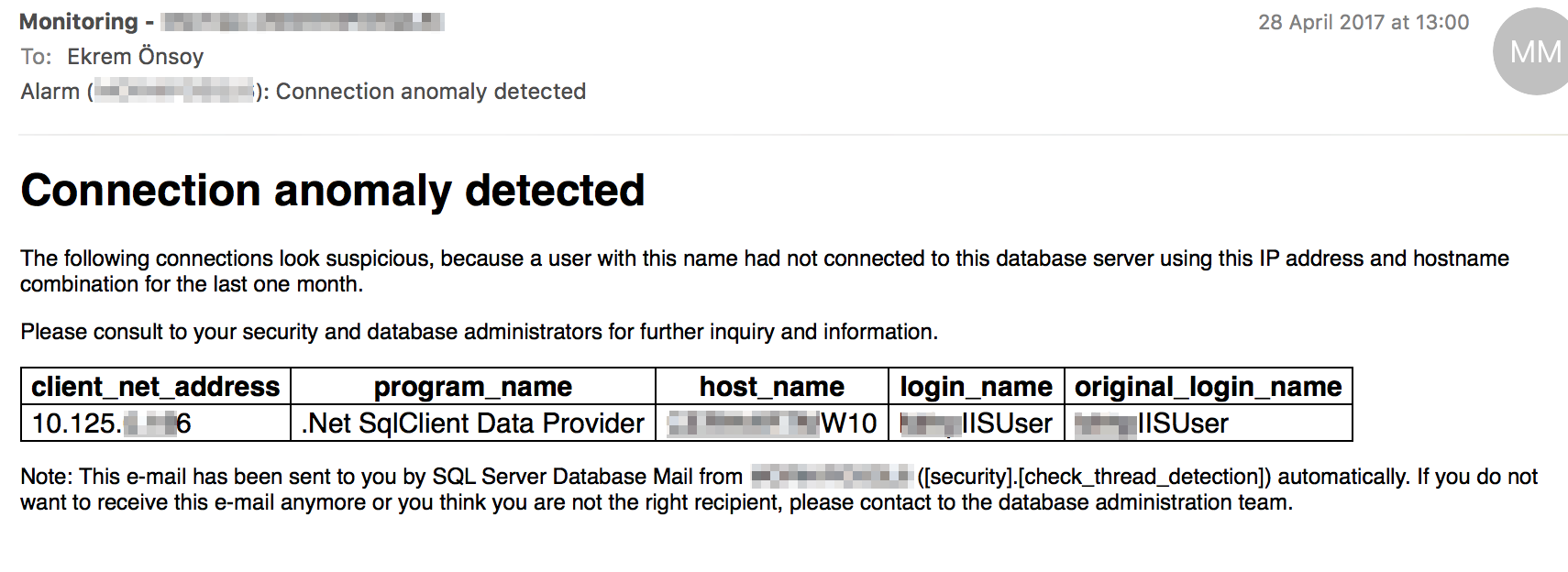
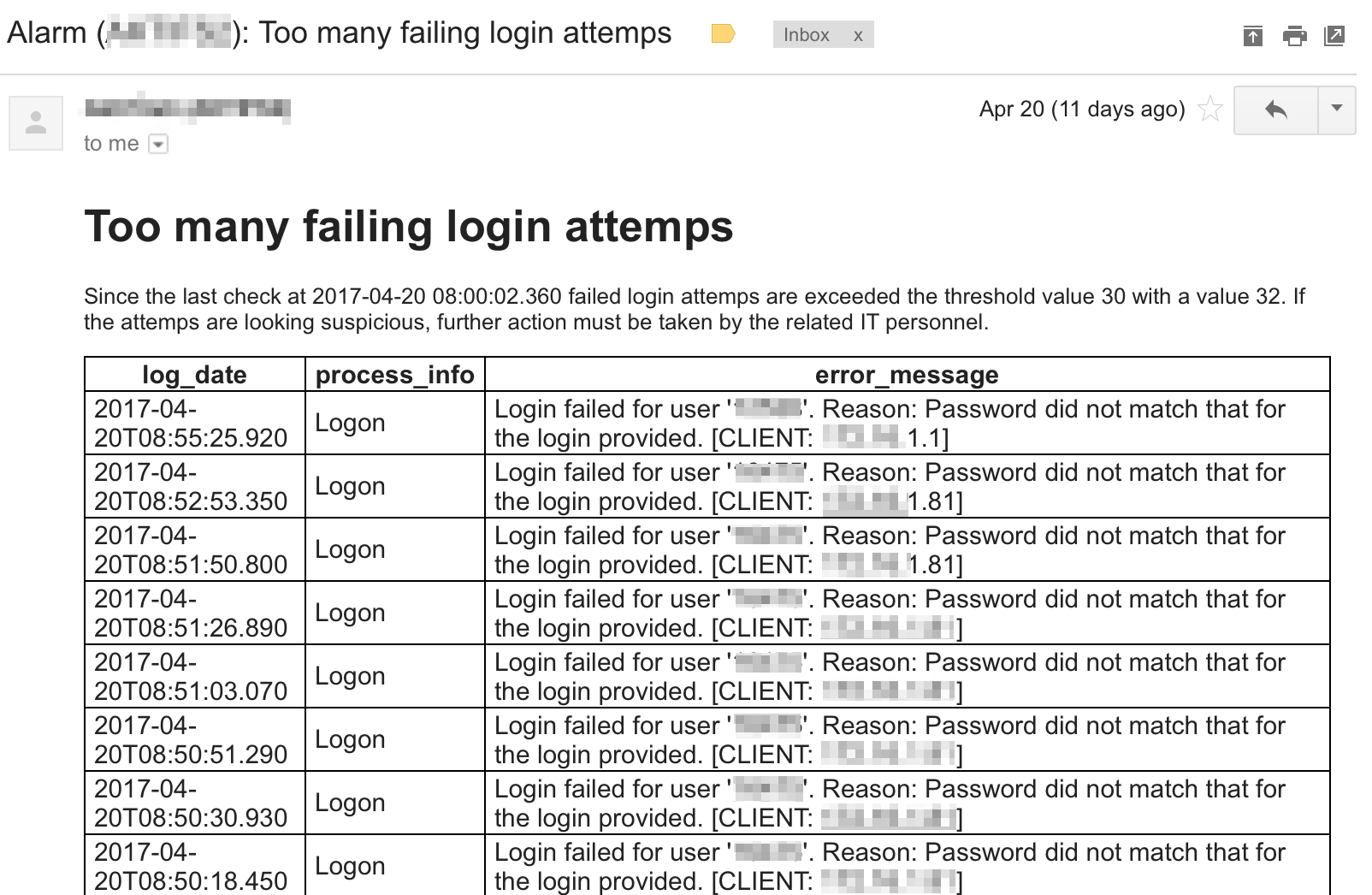
Örnek:
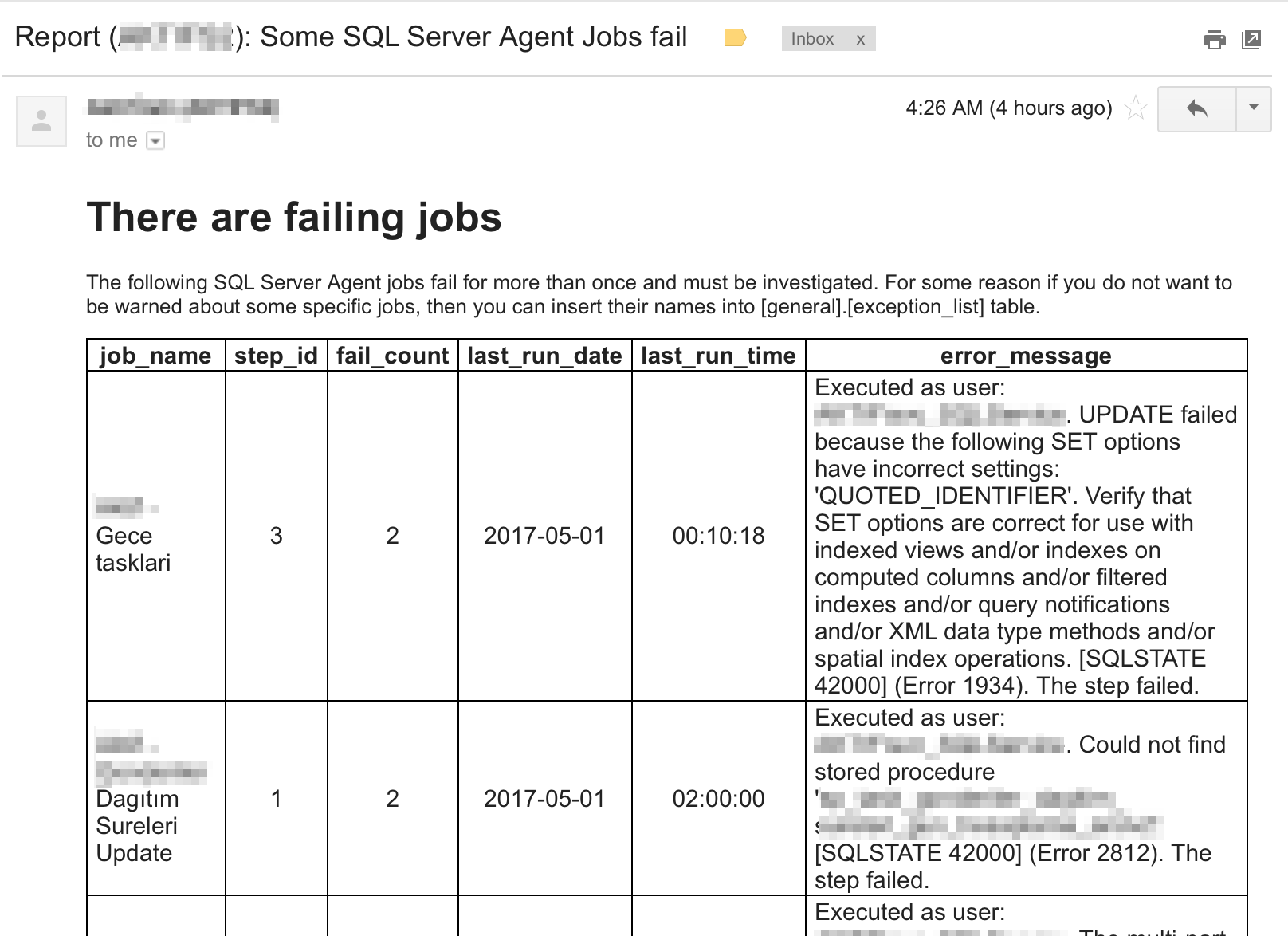
Bazı sistemlerde SQL Server Agent Job’larının çalıştırdığı işler çok önemlidir. Fakat durumun böyle olmasına rağmen Job’ların sağlıklı çalışıp çalışmadığı izlenmemekte, bazı Job’ların ayar boyunca hata aldığı fark edilmemektedir.
Aşağıdaki rapor ile hangi Job’ların hangi adımlarının ne zaman, kaç kere ve hangi hataları aldıkları izlenebilmektedir. Böylece ilgili ekipler sorunlar hakkında bilgilendirilir ve olası beklenmedik sorunların en kısa sürede önüne geçilir.
Bakım ve Destek Anlaşması seçeneklerimizi görmek için tıklayın! Eğer zaten kararınızı verdiyseniz, çalışma seçeneklerimizi değerlendirmek için arayın veya yazın!